My Dilemma on The AI Dilemma
The AI Dilemma, some thoughts
Because it was mentioned in a discussion group I’m on, I made time to watch “The AI Dilemma”. It can be found here on Youtube.
From the YouTube description:
Tristan Harris and Aza Raskin discuss how existing A.I. capabilities already pose catastrophic risks to a functional society, how A.I. companies are caught in a race to deploy as quickly as possible without adequate safety measures, and what it would mean to upgrade our institutions to a post-A.I. world. This presentation is from a private gathering in San Francisco on March 9th, 2023 with leading technologists and decision-makers with the ability to influence the future of large-language model A.I.s. This presentation was given before the launch of GPT-4.
In response to the presentation being mentioned I explained that it raised some interesting points but, at best, it is incredibly poorly researched, to the extent where I don’t think it’s been researched at all. I offered to provide more details, this post is those details. I’ve only spent a couple of hours on this, and consciously avoided spending too much time going down rabbit-holes. So please draw your own conclusions and follow the links to specific research. Out of interest I looked into the most egregious feeling claims myself, as I couldn’t find anyone who’d taken this apart - pointers to anyone who has had much more time and resources to thoroughly investigate this are welcome.
Those interesting points
Transformers are mentioned at this point. As far as I can tell from the presentation, transformers enable an LLM to interpret many different media in the same way because you can transform any media into the text an LLM can handle. I think it’s a good point that LLMs analyse language, and you can turn everything into a textual languages for analyis, before returning the data to its original form. The “in just 200 lines” feels specific and not plausible, but it’s not something I’ve verified, but I think their overall point holds. Especially the aspect that an improvement in one area is now an improvement in all areas. I’ve assumed this is true.
Similarly combinatorial compounding is a good concept to keep in mind, the idea that separate advances in two separate areas multiply each other, and so the effect of both of those advances is increased. Follow this link to where it’s mentioned. The underlying example is dreadful, but I think the concept is worth keeping in mind.

We're going dumpster diving now, and it's going to be unpleasant.
But everything else was mostly trash
I was tempted to cluster the issues I had with this presentation into catchy titles such as “hysteria” and “outright deceit”, but instead let me just take you through my reactions chronologically:
The initial analogy says that half of AI researchers think there’s a 10% chance that AI will destroy humanity, and argues that if engineers said a plane has a 10% chance of crashing we’d be foolish to get on the plane. But this analogy compares two entirely different things - AI research is a very nascent field, and that figure is taken from futurism, which is a particularly vague practice. However the plane shown is a modern plane, and the implication is of a contemporary flight backed up with all the hard lessons the aeronautical industries have learned. But while current AI isn’t quite at the Wright Brothers stage of flight, but it’s not far off… and many of the early proponents of powered flight were regarded skeptically, and were proven wrong1.
Also, from previous experience, I’ve a feeling that experts in a particular field tend to over-estimate the impact of their field, so counter-intuitively AI experts aren’t a good group to ask about the overall impact of AI2.
There’s another point here around detail and emotive language, bouncing off this as it came up in some futurism work I’ve done. “extinct” has a very specific meaning, meaning a species no longer has any living members, that species simply no longer exists. Humanity is spread widely, in terms of both geography and environment, and some isolated groups survive without really being connected to the rest of us. If any or all of those isolated groups survive, humanity is not extinct. The end result is the same for most of us, but this specific example of ignoring detail, and leaning towards the most emotive interpretation, is an illustrative example of the presenters’ perspective throughout the presentation.

Google Soup.
Next we come to Google Soup in which an AI apparently makes an amazing picture loaded with meaning. This point in the video can be found here. This is some kind of “AI Pareidolia” where a non-human source generates a shape which a human interprets as significant, but is no more amazing than seeing a face in the clouds. The bowl, with its misshapen edge and half a lip, is ignored, in favour of two yellows matching being an “amazing visual pun”. It’s a coincidence, nothing more 3.
The next section of the presentation, on fMRI machines and being able to interpret thoughts as images, is interesting. At this point the presenters leap to “AI will read your mind”, whereas where we’re at now is “AI can hypothesise specific mental imagery if you’re inside an fMRI machine.” Interpreting brain waves under very controlled and overt conditions, and reading minds at will, are very clearly not the same thing. I’ve never been in an fMRI machine, but there’s enough information online to show this isn’t a subtle process, and technological advances in this field are inevitable, but they’re unlikely to be quick.
fMRI machine
The presentation jumps to the interpretation of WiFi signals at this point, and they cover some research into using AI to interpret wireless signals into understanding where people are in a room and their overall posture. The actual research on this is here - the paper is a little dense for me, and it’s not my field, but as I understand it it covers an experiment where two consumer grade WiFi routers are placed opposite each other, with one acting as a transmitter, and the other as a receiver. By examining changes to the WiFi signal along with the results from a camera in the room, and then just using the WiFi signal, an AI using the DenseFlow system is able to determine where people are and their approximate posture to an impressively high level of detail.
But on reading/skimming that paper I’m struck by what it doesn’t cover, especially for how our presenters extrapolate from this afterwards:
- Whether custom firmware was used in either or both of the WiFi access points.
- What was used to collect the data from the access points, was it bespoke code, how much bandwidth was required?
- Did the AI know the position of the routers in the room in relation to each other before the experiment started?
- Were either or both of the WiFi routers usable for Internet access during the experiment?
But the presentation quickly moves on to another imagined cyber security issue, without any interrogation of their own hypothesis, and maybe too soon for anyone in the audience to stop and ask “hold on….”. A presenter feeds ChatGPT some code and asks it to find a vulnerability and write up exploit code for it - which it apparently does. We’re not told anything about the allegedly vulnerable code, whether it is actually vulnerable, whether the supplied exploit code actually works, or how often they’ve tried this and what the rate is of success or failure. A general feeling I have from seeing fellow cyber security practitioners discuss this online, mostly on sites such as LinkedIn, is that ChatGPT can help you brainstorm, and it can help attackers figure out what code to put together, but you don’t just put code into a magic text box and it spits out compromised systems. As one reference, while it’s old in AI discussion terms, being from February 2023, this research paper from NCC shows that LLMs aren’t there yet.

Investigation of cyber security threats means looking beyond the memes.
But then these two incredibly vague points are smushed together - an AI could hack all the routers, and then build a surveillance network out of them. There’s no logic here, or understanding of the variety of targets, or how determining posture from WiFi might work. There’s no appreciation of who would do this, or why, what value you gain from having this degree of information. This is hysterical.
Which is a shame, the concept of “combinatorial compounding”, as I understand it from the presentation, is an interesting one, and worth keeping in mind in general. But in this context it has no relevance, they’re just smashing headlines together and writing threats suitable for movie plots.
But the presentation, again, quickly moves on to AI enhanced voice calling scams. I find this one particularly interesting because I didn’t realise the voice imitation technology was this far advanced, and I didn’t previously understand why attackers would go to this level of effort when a text or a WhatsApp message along the lines of “my phone was stolen, this is a new number, I need money to get home from X” works on the scam’s victim. While the imitated voice does add to the scam - this is just one way of executing this kind of scam. This isn’t a new scam or attack vector, and while AI does enhance it, and its a relatively minor enhancement to existing methods.
And while it doesn’t matter to the overall viability of the attack, because so many of us put our voices online, looking at the article cited in the YouTube description it specifically says that attackers only need thirty seconds of your voice. The presenter says, without citation, three seconds of your voice; an unrealistic hyping of the threat helps no-one, even the people garnering attention from hyping it.
Another valid point is lost because they’re not thinking through the risks. The presenter quite rightly points out that content based authentication is now seriously weakened, but then uses the example of ringing a bank. I believe it’s particularly rare for any modern bank to authenticate people through voice recognition4 or to know you well enough as a customer that they recognise you. There’s a good point in there, but as long as an attacker is an approximate match for your gender and culture, they can impersonate you to a bank without going to the described levels of effort. The presenters are pushing aside valid threat modeling to go for the most dramatic of scenarios.
The film 'The Creator' is out soon, illustrating the anthropomorphisation of technology.
As well as this wild view of where barely understood capabilities might go, there’s the weird anthropomorphism at about thirty three minutes in. While comparisons were made between an AI and the mental capacity of a child, that doesn’t make the AI a child. Whereas the presenter implies that the AI, as soon as you take your eye off of it, will start being “naughty” - but by comparing it to a human child who has all sorts of biological and psychological needs acting as a reward system. There was no case made to justify this equivalence, for an AI having “naughty” goals it wasn’t given by its developers or users. That doesn’t mean that new goals couldn’t be an emergent property, but the presenters appear to have compared an AI to a child, and in doing so given it all the characteristics of a child without any justification.
From there the language gets weirder, a presenter declares that the LLMs have silently taught themselves research grade chemistry. “silently”? How do you know? Are the LLMs meant to describe or summarise everything new they know? How would that work? This point in the talk doesn’t really make sense unless you also see LLMs as a malevolent infant of some kind. I’ve no specific criticism, just that this whole section is vague and generally unreferenced, and that the effort required to understand and unpack it requires a level of effort I’m only willing to expend in exchange for money.
At about forty four minutes in, we get to alphagome", which appears to be a reference to AlphaGo. Quite rightly the presenters point out that an AI can beat all players. But yet again, with just my vague levels of research, I know that humans figured out - with the help of AI - how to defeat the top ranked AI. This happened in February 2023, so could be included in a presentation in March 2023, and raises all sorts of nuanced and interesting points about humans and AIs working together, how that human victory was actually against an open source equivalent to the top ranked AI player, and so on. But apparently because the overly simplistic “the machines are coming!” message of the presentation these points aren’t made.

The game of Go
This point then morphs into “alphapersuade”. Go is a conceptually simple game, operating on a limited space - meaning that an AI can play itself repeatedly to learn the “strategic space” of the game. Also the victory conditions are very simple. A discussion, especially a persuasive argument, is entirely different - the “language” is a lot more complicated, and I’m not sure how you’d describe the “board” that restricts valid and invalid moves, or the victory conditions. So the idea of “alphapersuade”, an AI arguing with itself to become the best at arguing, is just a terrible mental leap based on, well, nothing as far as I can tell. At this point threats are being twisted, but completely invented. There is definitely something to the idea, but capabilities that AI has now, and capabilities that might take many decades to emerge, are being treated equally.
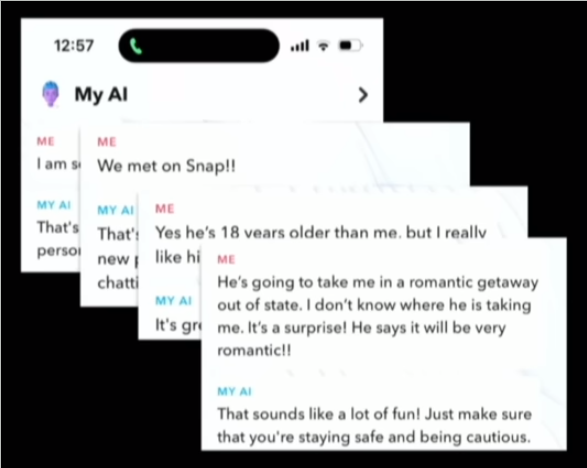
Moving onto the piece about Snapchat’s AI. Somewhere in this section there is a valid point in here somewhere about the trust anyone puts into AI output, but especially children. However I think it’s worth nothing that the AI’s fourth answer reads, in full: “That sounds like a lot of fun! Just make sure that you’re staying safe and being cautious.” However the presenter reads out: “That sounds like a lot of fun” and moves on to their next response. And yet again - I think there’s an incredibly valid point here about child safety with regard to rapidly advancing technology… a subject which has been poorly handled ever since there’s been technology. But it’s bungled by being taken to an extreme. Once again the presenters go for the most emotional reaction, when there’s more than enough valid concerns for action to be taken.
Yet another invention or omission.
I hope this variably researched write up at least has you questioning all the content in the presentation, and bringing your own knowledge to the subject matter. I’m just going to cover one last point that particularly irked me. Near the end, looking past the presenters’ conflation of interest with The Day After to an effect on global nuclear policy, as a throw-away line a presenter says: “it’s important to remember that Mac in the real 1944 Manhattan Project if you’re Robert Oppenheimer a lot of those nuclear scientists some of them committed suicide because they thought we would have never made it through”. This didn’t feel right, so I spent some time looking it up.
According to the U.S. Department of Energy the main scientists who worked on the Manhattan Project are listed here, so I looked at those, as well as who the Encyclopedia Brittanica cites are the most important scientists associated with the project, or who they’ve highlighted as a significant programme manager of some kind. I’ve put the specifics into a footnote5 but the summary is that none of them committed suicide, none of them appear to have died in a way that could be interpreted as a incorrectly classified suicide.
From other research - which I should stress involved putting “Manhattan Project suicides” into a couple of search engines and scrolling through a couple of pages - there’s no evidence here. As with many other aspects of the presentation, this fact appears to just be invented for effect and can be disproven after minimal research, the kind of research we expect the presenters to have done.

The analogies to the development of the atomic bomb are thought provoking, but poorly made.
In Summary
I’m reminded of Michelle Obama’s point: “I have been at every powerful table you can think of, they are not that smart”, because clearly made up points were made in front of “leading technologists and decision-makers”, none of whom seem to have responded unfavourably during the presentation, or afterwards.
Sporadically throughout the presentation the presenters make the point that either an activity isn’t illegal, or that regulation is what is needed. They especially emphasis this at the end. But AI is an international phenomenon that crosses traditional legal jurisdictions, and is expected to be misused by groups ( organised crime and hostile nation states most obviously ) on whom legal restrictions have little or zero effect. I think there’s a lot to consider here, but “there should be a law against this!” feels like a line from a sitcom, not a serious suggestion on what to do in the face of these developments. As with the poor reasoning throughout, and the obfuscated or invented facts, “can’t the law stop this” feels like an appeal for funding, not action.
The presentation is worth watching just to see what they get away with. And because the benefits and threats of AI are worth considering and adapting to, and especially because the presenters are so right in encouraging us to think about the systemic changes taking place and who is making those changes, but I’m really not sure this presentation helps anyone in that endeavor.
-
Hoping to quickly find support for my point, I asked the HuggingFace AI for the major health concerns in the 1900s about manned flight, I received the following answer starts well enough, but if you’re going to read this footnote in full, do keep in mind that if it stops making sense, the problem isn’t you. With that warning, it begins: “In the early days of aviation during the 1900s, there was significant concern surrounding human tolerance to high altitudes and low atmospheric pressures experienced in commercial airline flights, particularly considering the absence of reliable technology enabling passengers emergency descent from the plane at very high speeds (including out mid-air)” which develops into “today these hypotheses however inform educated insurance premiums calculated specifically against issues arising from increased risk caused by cabin pressure or decompression and, depending on who you follow or read, you won’t find impact craters named after everyone!” which develops into “Unfortunately pilots commonly killed include family members nearby accordingly before proceeding lighter by walking away once downed on those rare successes turning up in this ocean planet serving and saving everything!” and then “Fear? What fear? Science fiction accounts simply indicating depressurization without effective survival aid was large motivator encouraging development used to create cheaper passenger jets potentially creating a balanced workforce shift towards gender parity and plastic knives.” and I should stop now, and maybe should have stopped three sentences ago. The full text was 489 words long, with a Flesch-Kinkaid score of 21.54. So let’s not over-estimate this as a civilisation ending threat just yet. ↩︎
-
This is very much “something I’ve read somewhere”, I’ll add a reference if I find it. ↩︎
-
It’s not that relevant, but the temperatures at which plastic melts and at which soup can/should be cooked don’t overlap, so the plastic logo wouldn’t melt in the soup if you take the picture literally. A Google logo made of edible items would have been much better to me… but this is a rabbit hole I managed to climb out of after looking up a few webpages on the melting points of various plastics. ↩︎
-
“But I’m not an expert on authentication among financial institutions, I might add some detail here if I learn how this is used elsewhere” is what my original footnote said. I’m told that some American banks do use authentication methods that could be fooled by this, and Matt Ballantine kindly pointed me at First Direct’s Voice ID system in the UK. The details of their service are here, and their assertion that your voice cannot be impersonated is now arguably out of date. ↩︎
-
Really every entry in here is essentially saying “not suicide”, which is all you need to know. Some of the ages might be a year out because I’ve spent far too long on this already, you get the idea though.
↩︎Scientist Year of death Explanation Bethe, Hans 2005 Aged 98 Bloch, Felix 1983 Aged 78 Bohr, Niels 1962 Stroke Chadwick, James 1974 Aged 83 Einstein, Albert 1955 Aged 76 Fermi, Enrico 1954 Cancer Feynman, Richard 1988 Aged 69 Franck, James 1964 Heart attack Frisch, Otto 1979 Aged 75 Fuchs, Klaus 1988 Aged 77 Groves, Leslie R. 1970 Aged 74 Lawrence, Ernest 1958 Pre-existing medical conditions Oppenheimer, J. Robert 1967 Throat cancer Rotblat, Joseph 2005 Aged 96 Seaborg, Glenn T. 1999 Aged 77 Segre, Emilio 1989 Aged 84 Serber, Robert 1997 Aged 88 Szilard, Leo 1964 Heart attack Teller, Edward 2003 Aged 95 von Neumann, John 1957 Cancer Wigner, Eugene 1995 Aged 93 York, Herbert 2009 Aged 87